
Clairvoyance 是怎麼開發的
我寫了一個 chrome 的插件,
能夠讓求職者在人力銀行的職缺下面留言討論。
聽起來是很平常的需求,不過各大人力銀行就是不做這個功能,
所以我想看看假如有這個功能會不會對求職有正向的幫助。
下載的連結在這裡: Clairvoyance - 求職天眼通
目前還在 beta 階段,可能會有些 bug,
可以到粉絲頁留言,
或是在 github 上直接發 issue。
下面就來筆記一下為什麼要做這件事,以及怎麼做到的。
用的技術就是以下列的這些
front-end: reactjs、redux、redux-saga
back-end: aws-lambda, dynamodb, serverless-framework
目前只支援 104 和 1111,至於 yes123,後面會再提到為什麼暫時沒做。
下面來簡介一下是怎麼做出來、以及為什麼要做。

Introduction
為什麼要做這件事情?
其實我比較想問的問題是:為什麼不要做這件事情呢?
我們買商品的時候,在拍賣網站上就可以看到買家對店家的評價、對商品的評價,
而求職的時候,卻一定要到其他討論區、其他網站,
才能看到其他人對於該職缺或公司的評價,
這其實是一件很不自然的事情,
再說種種擔心對手黑函還是求職者亂抹黑什麼的,
嗯⋯⋯電商其實也會遇到這樣的事情,
總之想不到一個很合理的解釋,
唯一能想得到的解釋就是「盈利模式」。
目前我們在人力銀行上找工作,其實是不用付錢的,
但是企業卻是要付費用才能張貼職缺。
合理的推斷,
其實我們這些求職方就是人力銀行的商品,
真正的使用者是那些企業用戶(資方),
而讓使用者能夠留言討論的功能,
可能會讓部分企業用戶不想使用。
看看各大人力銀行上,許多職缺都喜歡「面議」
就知道資訊不對稱對於資方來說是一件多麼正常的事情
我不會認為敘薪是簡單的,
但給個底價,避免浪費彼此時間這件事,
真心不應該難道哪裡去。
否則騙人去面試的行為,其實跟詐騙集團一樣可恥
無論背後的動機是什麼,
既然人力銀行有其考量不做這件事、我又認為有需要的話,
那與其動嘴巴抱怨台灣的求職平台不好用,
不如自己來做做看,看能不能為台灣險峻的就業環境帶來一些幫助。
在做這個 side project 之前,
其實我自己找工作從來都沒有用過各大人力銀行,
這次還花蠻多時間在探究自己到底為什麼不用這些平台,
以及他們到底缺少了什麼。
What is clairvoyance
為什麼是這個名字?
命名一直是蠻困難的一件事情,
本來有想過要叫什麼 job-bar in in der。
不過後來還是靈光一現跑出這個單字:
Clairvoyance。
為什麼要取這個名字有兩個版本的故事:
高級版本
Clairvoyance,可以翻作洞察力或是透視,
主要是希望透過求職者彼此分享經驗,
來透視一個職缺的好壞,或是否適合他。
真實版本
其實就是 google 天眼通,
翻譯的第一個單字就是 Clairvoyance,
然後我蠻喜歡周星馳的賭聖,所以就這樣命名了。
Why is Clairvoyance
其實會做這個 project ,
有一部分是因為自己最近開始接觸分散式運算,
開始了解去中心化的想法,
我認為與其把所有對平台上職缺的評論給「集中」起來,
不如將它分散到各自原本的職缺下方,
然後再將相同職缺的評論同步。(Consistency)
這樣的做法是更合理,而且使用起來更有效率的。
Architecture
假如說一開始我知道會這麼搞剛的話,
應該就會放棄了⋯⋯
整個 project 主要分成三塊:
gui:Chrome extension 的 UI
-
- 處理後端的資料
-
問題:chrome 的插件是明碼的,假如要在上面做認證,就要在 chrome 上面直接放 secret key,這樣做一點都不 secret
解法:開了一個 serverless 的 api 專門來做這件事情,在 repo 的 README 裡面蠻詳細的紀錄如何做到,所以這篇裡面不會贅述這一點。
這裡畫了個很粗略的圖,看一下會比較有概念:
clv = clairvoyance
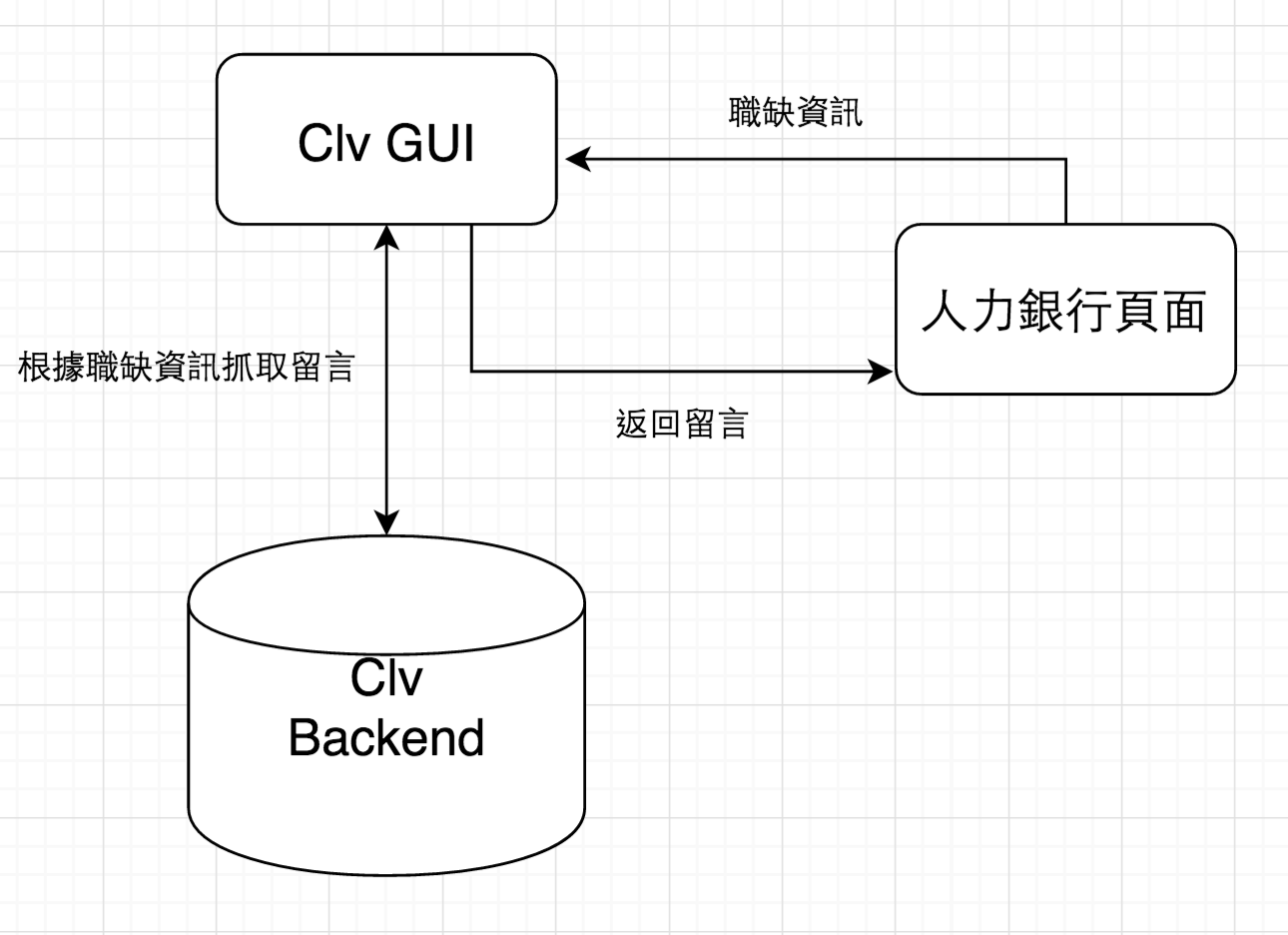
其實 backend 就是處理留言、工作、使用者,
而我並不想自己維護一台機器做這些事情,
所以我用了 serverless 的方式去解決,
想要瞭解更多關於 serverless 基礎的人,
可以看一下這篇舊文:淺析 serverless 架構
是我剛學習 serverless 時做的筆記,
同時也是繁體中文裡面最詳細的新手教學。
就算簡體中文其實也是啦
前端的話,有一些比較討厭的部分就是非同步的處理,
但這裡 saga 很簡單的幫我 handle 處理好了,
而且還給了相當好的測試性,
這點非常非常重要,
測試省掉了我不少 debug 的時間。
中間大概重構了一兩次
Back-end
首先就是要先訂好 schema,以及各個資料相互的關聯性,
這裡有用到 GSI 來建立查詢的 index,
雖然我們會用公司名稱以及職缺名稱來查詢,
但這兩樣東西都不適合拿來當作 Primary Key,
我覺得看完這篇官方的最佳實踐,
就已經差不多能掌握怎樣去設計一個拿 dynamodb 當作資料庫服務的心法,
剩下的只是把資料長怎樣想清楚而已。
使用 DyanmoDB 時,會考慮到資料一致性的問題。
但畢竟這不是一個非常要求即時性的服務,
所以我對於最終一致性這件事情是有相當高的容忍度的 :D
什麼是最終一致性呢?
就是我們不保證每個節點讀取資料時,資料都會是相同的,(強一致性)
但隨著時間過去,每個節點上的數據會回歸一致。
這只是很粗略的說法,接下來幾個禮拜可能會寫一些和分散式有關的,
就會提到這一點。因為一致性對於分散式運算來說一直是一個很頭痛的問題。
Front-end
我選擇使用 React 及 Redux 的原因蠻單純的,
因為我最近常在工作上用到它們。
Reactjs+ CSS Module
CSS 的命名一直是一個很難解的問題,這裡我的想法是無論再怎麼有效的規範,都是軟性的,CSS 的特性讓全域污染這件事情變得難以避免。但 CSS Module 卻可以讓所有的 class 都變成 local 的,
React 以 component 為主的開發模式,跟 CSS Module 搭配起來相當不錯
Redux Saga
處理非同步的資料流(像是從 backend fetch 資料)
有些 UI 上的 transaction 都可以在 saga 處理
使用 saga 的重點是「測試」,effect 的概念讓測試變得簡單很多,少了各種 mock
其實這裡本來想用 Rx 搞定,但工作上真的用了太多 Saga,現在有點回不去了⋯⋯
假如你未曾瞭解過 saga,可以看一下我的這篇文章 Saga Pattern 在前端的應用
UX
這裡不是要說有著多精美的 UI,
是自己開發時,總覺得我開發的東西,真他媽怎麼用怎麼順手啊!
實際上別人一看到時,卻常常完全不是這麼一回事。
最好的方法就是請朋友幫忙用一下,
然後什麼都不要跟他說,也不要有任何預先的假設。
沒錯,就算你有說明書,User 就是死都不會看(我也是)
很常發生的事情就是 User 完全不知道你想幹什麼,
留言區塊那邊一開始就是這麼一回事,
所以如果有人說你做的東西「太工程師」、「太 geek」,
大概就是這個樣子。
感謝我的幾個被我巴著幫忙測試的朋友。
m (_ _) m
Conclusion
目前只支援 1111 以及 104,
yes123 的 url,有那麼一點難以預測⋯⋯
不過也是因為這個 Project ,可以感覺到各個求職平台是否用心,
未來要加入的功能應該有以下幾項:
個人留言職缺的追蹤
Facebook 粉絲頁的機器人
- 幫忙發布熱門討論的職缺
重構
- 比較有問題的應該是建立職缺那裡的 code 很醜 XD
其實我知道這個 beta 版本還有許多可以更好的地方,
不過我更想瞭解這個插件是不是真的能解決一些問題,
所以就先釋出這個 beta 版了!
假如有什麼想問的問題也可以留言、發 issue 或直接跟問我,
對我來說,不只是想 build 一個小小的插件,
我想造出一個對求職者來說真正透明友善的環境,
我知道一定會有蠻多人覺得這真是 too young, too naive 的想法,
不過不試試看,怎麼會知道結果怎樣勒?
- 下載位置:Clairvoyance - 求職天眼通